Проблема дублей достаточно распространена среди владельцев сайтов. Это происходит, когда ряд страниц имеют совпадает по содержанию, но имеет разные URL. Здесь используем атрибут rel canonical, чтобы указать поисковику каноническую ссылку, которую он и будет выдавать при запросе. Остальные он будет считать неканоническими и не станет показывать пользователям.
Дубли появляются из-за недоработки вебмастера, либо в результате автоматической генерации страниц.
Случаи, в которых используются канонические ссылки
- вам необходимо, чтобы при запросе пользователь попадал на конкретную страницу;
- контент располагается на нескольких страницах одного домена, и вы хотите связать переходы;
Предположим, в вашем интернет-магазине есть желтое платье. Оно находится как на странице «Платья», так и на странице «Коктейльные платья». В таком случае при указании канонической страницы ссылки с других сайтов на «Коктейльные платья» будут связаны с основной страницей со всеми платьями.
- для упрощения статистики (материалы размещены на нескольких URL, и это усложняет получение общей статистики);
Как и в предыдущем примере, если искомое желтое платье находится на страницах «Платья», «Летние платья» и «Коктейльные платья», будет тяжело собрать общую статистику переходов на страницу с желтым платьем.
- для определения рейтинга исходной страницы (он должен быть выше, чем у повторяющихся);
- чтобы упростить роботу индексацию сайта.
Важно! Помните о том, что неканонические страницы при этом в поиск не попадут.
Однако в них может содержаться информация, отсутствующая на исходной. Но пользователь не сможет найти ее. Так что без особой необходимости не указывайте каноническую ссылку вручную.
Если все же решите это сделать, отталкивайтесь от посещаемости страницы и наличии и количестве внешних и внутренних ссылок на ней (чтобы ПС не проиндексировала все страницы, на которые те ведут).
Как правильно реализовать
Каждый из способов прописать rel canonical обладает своими преимуществами и недостатками, так что придется выбирать, какой конкретно подойдет именно в вашем случае.
В html
Добавляем в код в раздел <head> элемент с rel=«canonical» и ссылку на нужную страницу:
<link rel="canonical" href="https://example.com/dresses/green-dresses" />
Важно! Для мобильной версии добавляем <link> с атрибутом rel=«alternate» и ссылку на страницу:
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/dresses/green-dresses">
В Sitemap
Подойдет для больших сайтов. Все страницы, указанные в Sitemap считаются каноническими. Робот определяет дубли по контенту. Однако есть риск, что при обходе сайта указанная информация будет учитываться.
В заголовке http
Этот способ можно использовать, если у вас есть доступ к настройкам сервера и вы знаете язык PHP и/или умеете пользоваться конфигурационным файлом сервера .htaccess. Его также не рекомендуется использовать для html — он предназначен для канонизации таких форматов, как URL.
Если вас это устраивает, то укажите канонический адрес в настройках сервера в заголовках HTTP:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"
Важно указать именно абсолютный путь:
Правильно: http://www.site-name.com/downloads/ blue-shorts.pdf
Неправильно: /downloads/red-shorts.pdf
Плагины для WordPress
На этой платформе можно использовать несколько плагинов.
Yoast seo
Открываем в плагине настройки и вводим адрес в строку Canonical URL:
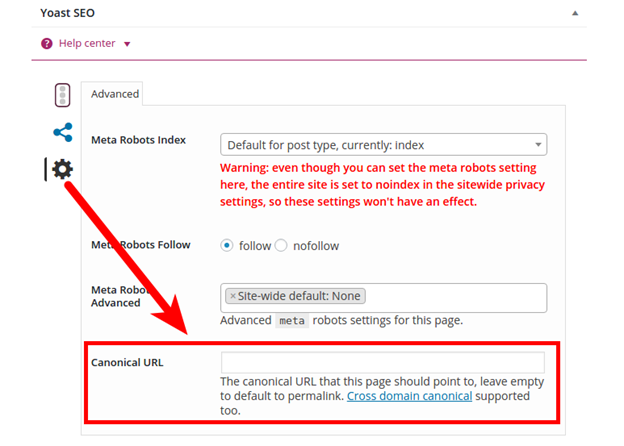
В Yoast SEO ограниченный функционал — в поле есть возможность указать только один необходимый канонический адрес. А еще в плагине существует проблема с пагинацией: скажем, если товара на странице слишком много, то появляется нумерация страниц, в таком случае Yoast SEO канонизируют каждую из этих страниц.
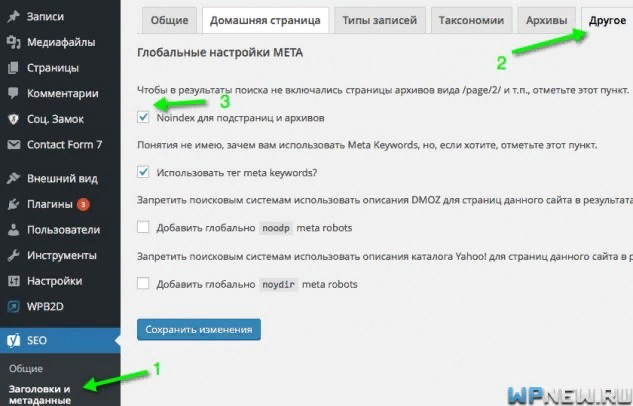
Чтобы решить вопрос, открываем в плагине вкладку «Заголовки и метаданные» -> «Другое» и ставим галочку «Noindex для подстраниц и архивов»:
All in one SEO pack
Открываем плагин и отмечаем галочками пункты «Канонические URL» и «Запретить пагинацию для канонических URL» (для избежания проблемы с пагинациями):
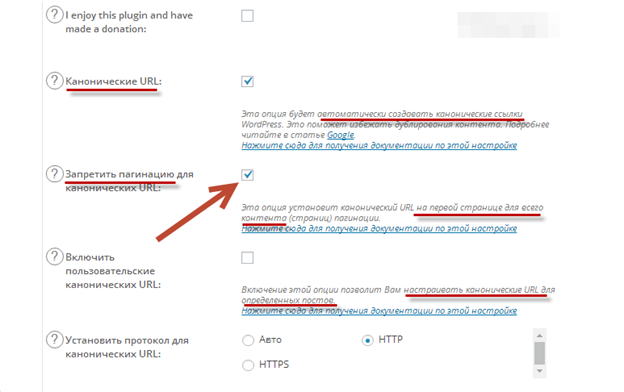
Минус в том, что по умолчанию канонической указывается первая страница, а остальные в ПС не отображаются. Если нахождение неканонических страниц в поиске необходимо, плагин вам не подходит.
Например, когда пользователь ищет цитату из книги или ответ на вопрос на форуме, где канонической отмечена первая страница, а искомая фраза находится за ее пределами. Ранее эту проблему можно было решить, перейдя на Platinum SEO pack, но с 16 апреля 2019 года он был закрыт из-за проблем с безопасностью. Сейчас его невозможно скачать.
Каких ошибок избегать при использовании rel canonical
- нерабочая страница: имеется в виду, что прежде чем установить страницу как каноническую, нужно убедиться, что она работает, а не выдает ошибку 404 или редирект, или стоит как noindex;
- URL принадлежит другому домену: если одному человеку принадлежит несколько доменов, то их нельзя связать, используя rel canonical.
- указано несколько адресов или их цепочка;
- атрибут неправильно прописан: rel=»canonical» ставим строго внутри открывающегося и закрывающегося тега, указываем только один раз, перед ссылкой, которая прописана как полный адрес с доменом.
Знаете другие способы применения rel canonical? Пишите в комментариях!

основы основ-)