Дубли — веб-страницы с одинаковым содержанием, но разными адресами. Данная проблема возникает как из-за недоработки или ошибки вебмастера, так и в результате автоматической генерации.
Почему стоит избегать дублей?
Дубликаты негативно влияют на продвижение сайтов из-за того, что уникальность контента на этих страниц равна нулю.
Допустим, вы на своем сайте опубликовали статью, поисковики проиндексировали ее. Буквально через неделю по результатам анализа обратных ссылок вы обнаруживаете, что на эту статью ссылаются в других блогах.
Благодаря этому профиль ссылок растет, но позиции статьи по ключевым запросам никак не меняются. А все потому, что авторы других блогов ссылаются на дубль страницы.
Дубли приводят к:
- Неправильной идентификации релевантной страницы — той, что наиболее точно отражает информацию по поисковому запросу. Допустим, у продвигаемой страницы есть дубликат. Вы вкладываете средства, благодаря чему она появилась в Топ-10 поисковой выдаче, но в какой-то момент робот исключает ее из индекса и заменяет на дубликат. Из-за этого оригинальная страница привлечет меньше трафика.
- Увеличению времени, которое тратится на переобход сайта поисковыми роботами. У робота ограниченное время на сканирование сайта. Если дублей будет много, то он не сможет дойти до оригинальной страницы, что приведет к более длительной индексации.
- Наложению санкций поисковыми системами. Поисковой алгоритм может посчитать, что дубли создаются намеренно, чтобы манипулировать результатами выдачи.
- Увеличению трудозатрат. Особенно это актуально, если не удалять дубли сразу после обнаружения. Если их накопиться слишком много, то физически устранить все будет сложно. А это приведет к появлению ошибок.
Виды дублей страниц
Дубли могут быть полными и частичными. Последние сложнее обнаружить, однако они влияют на ранжирование сайта.
Полные дубли
Они имеют идентичное содержание, однако доступны по разным URL-адресам. Примеры полных дублей:
- Адреса могут содержать слэши и быть без них, например: https://site-name.ru/catalog или https://site-name.ru//////catalog.
- Наличие двух протоколов: https://site-name.ru/catalog и http://site-name.ru/catalog.
- Наличие www или его отсутствие: https://site-name.ru/catalog и https://www.site-name.ru/catalog/
- Адрес с одним из окончаний: index.htm, index.php, index.html, home, default.asp, default.aspx, например, https://site-name.ru/home.
- Использование букв разного регистра, например, https://site-name.ru/catalog и https://site-name.ru/Catalog.
- Изменение иерархической структуры URL-адреса, например, https://site-name.ru/catalog/igrushki_dlya_devochek и https://site-name.ru/igrushki_dlya_devochek/catalog
- Наличие в адресе utm-меток (дают аналитическую информацию) и других, реферальных ссылок, например, https://site-name.ru/?yclid=321.
Частичные дубли
На них размещен одинаковый контент, но с некоторыми отличиями в элементах. Примеры:
- Дубликаты на карточках товаров и страницах категорий.

 Чтобы предупредить образование дублей, рекомендуется использовать разные описания товаров.
Чтобы предупредить образование дублей, рекомендуется использовать разные описания товаров. - Дубликаты могут появляться на страницах для печати, скачивания или поиска.
Как найти дубли страниц?
- Проверить, доступен ли сайт сразу по двум протоколам: HTTP (http://site-name.ru/) и HTTPS (https://site-name.ru/). Если в окне браузера открываются обе версии, то проблема с дублями точно существует.
- Проверить доступность сайта со слэшем в конце (https:/site-name.ru/) и без него (https://site-name.ru).
- Проверить, доступен ли сайт с WWW (https://www.site-name.ru/) и без этих букв (https://site-name.ru/).
- Воспользоваться специальными инструментами для вебмастеров Яндекс и Google. Наличие дубликатов можно увидеть в разделе «Оптимизация HTML» в Google Search Console:
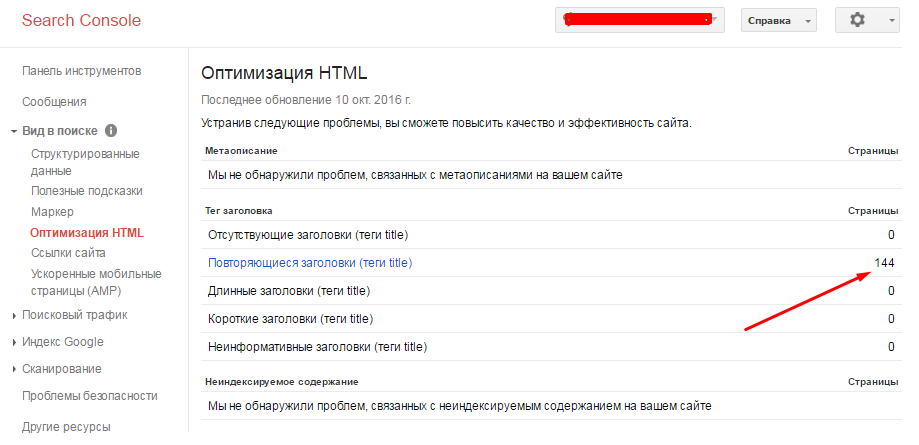
Или «Индексирование — Проверить статус URL», если работа проводится в Яндекс.Вебмастер. Для поиска дубликата страницы, нужно ввести ее адрес в специальное поле. В появившемся результате нужно нажать кнопку «Подробнее», после чего можно увидеть адрес дубликата:
В появившемся результате нужно нажать кнопку «Подробнее», после чего можно увидеть адрес дубликата: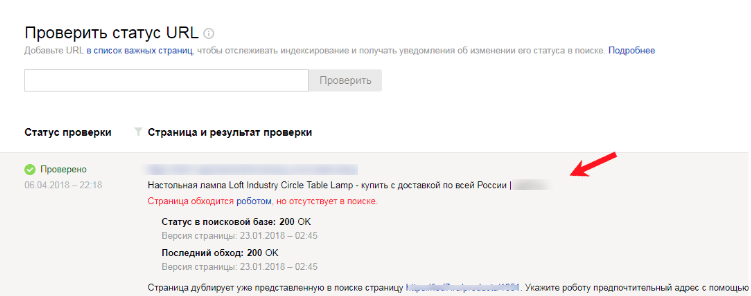
- Выполнить расширенный поиск Google, для чего в расширенном поиске нужно ввести адрес главной страницы сайта. Система предоставит общий список страниц в индексе. Если же указать адрес не главной страницы, а той конкретной, которая проверяется на наличие дублей, то в списке будут все дубликаты в индексе. Выглядит это так.
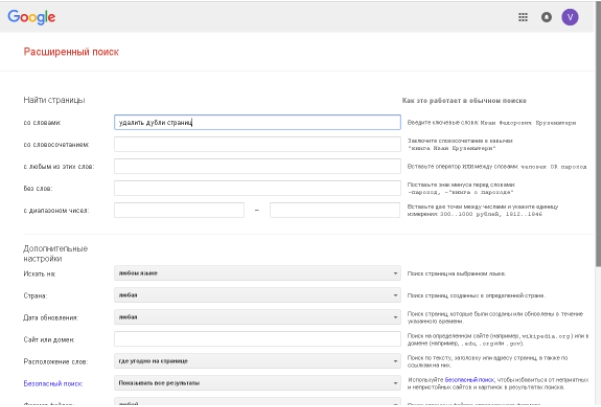
- Воспользоваться бесплатной версией инструмента Screaming Frog SEO Spider, которая дает возможность просканировать до 500 URL, чего вполне достаточно для небольшого веб-проекта. Доступна и платная версия. Оба варианта ищут не только дубликаты по адресам, но и идентичные title и description.
- Воспользоваться программой Netpeak Spider. Она легко находит дубли страниц, текста, метатег и даже заголовков Н1.
- Воспользоваться программой Xenu Link Sleuth, которая способна найти полные дубли и выполнить аудит сайта.
- Посетить seo-платформу Serpstat, там есть блок анализа дублированного контента на сайте.
Удаление дублей страниц
301 редирект
Это автоматическое перенаправление старой страницы на новую. После настроек редиректа боты видят, что по данному URL страница не доступна и перенесена на другой адрес. Благодаря этому удается передать ссылочный вес с дубликата на оригинал.
Данный метод эффективен в том случае, если дубли появились из-за:
- проблем с использованием слэшей в адресе;
- наличия букв разного регистра;
- изменения иерархической структуры адреса.
Например, 301 редирект способен перенаправить бота с https://site-name.ru////catalog на https://site-name.ru/catalog.
Файл robots.txt
С помощью этого файла вебмастер может рекомендовать ботам те страницы, которые лучше посетить и те, что не стоит сканировать. Для этого используется директива «Disallow».
User-agent: *
Disallow: /stranica
Если дубль был проиндексирован или на него есть ссылки, то страница все равно будет в поисковой выдаче. Инструкции в robots.txt имеют рекомендательный характер, поэтому гарантии удаления дублей нет.
Метатеги
Чтобы этот метод сработал, нужно на дублях в блоке <head> разместить один из этих тегов:
- Метатег
<meta name="robots" content="noindex, nofollow>запрещает роботу индексировать документ и переходить по ссылкам. В отличие от файла robots.txt этот метатег является прямой командой, поэтому поисковой робот не будет ее игнорировать. - Метатег
<meta name="robots" content="noindex, follow>запрещает роботу только индексировать документ, а переход по ссылкам — нет.
Атрибут rel=«canonical»
Атрибут поддерживается только поисковой системой Google, в то время как Яндекс этот тег проигнорирует.
Данный метод используется в том случае, если страницу удалять нельзя и ее нужно оставить доступной для просмотра, например, на страницах сортировок или фильтров.
Также этот тег используется для удаления дубликатов, в адресе которых имеются utm-метки, или если на странице контент представлен на нескольких языках.
Указывать нужно адрес той страницы, которая должна индексироваться. Например, на сайте интернет-магазина есть категория «Игрушки для девочек». В ней можно выполнить фильтрацию товаров по бренду, цене, возрасту, типу.
Для них канонической является общая страница категории. Чтобы сделать ее такой, в ее HTML-коде необходимо разместить атрибут rel=«canonical» между тегами<head>…</head>. Например, <link rel=«canonical» href=»https://puzat.ru/» />.
Что нужно знать о дублях страниц?
- Дубли — разные страницы сайта с одинаковым контентом.
- Возникают дубликаты из-за ошибок вебмастера, изменения структуры сайта или автоматической генерации.
- Наличие дублей на сайте может привести к ухудшению индексации, изменению позиций в выдаче поисковой системы, уменьшению ссылочной массы.
- Найти дубли помогут программы Screaming Frog SEO Spider и Netpeak Spider, инструменты для вебмастеров от Яндекса и Google.
- Удалить дубликаты можно с помощью 301 редирект, файла robots.txt и прямых команд роботу поисковиков.

